ATACOM: Safe Learning on the Constraint Manifold
Puze Liu, Jonas Günster, Jan Peters, Davide Tateo
German Research Center for AI
TU Darmstadt
Reinforcement Learning in Robotics
Robot Parkour (2023), Qi Zhi Lab, Stanford
Robot Soccer (2023), Deepmind
Humanoid Backflip (2024), Unitree
- Policy trained in simulation
- Domain randomization to increase the robustness
- Zero shot transfer without real-world fine tuning
- Simulator that captures environment variations
- Failure in unforeseen scenarios
- Robot lacks of performance improving capability
Robot Parkour (2023), Qi Zhi Lab, Stanford
Robot Soccer (2023), Deepmind
Humanoid Backflip (2024), Unitree
Robot should learn while interacting with the real world
Safe Exploration
$$ \begin{align*} \max_{\pi} \quad & \mathbb{E}_{\tau \in \pi} \left[ \sum_{t}^{T} \gamma^t r(\vs_t, \va_t) \right] \\ \mathrm{s.t.} \quad & k(\vs_t) < 0 \end{align*}$$
Robot dynamics $\dot{\vs} = f(\vs) + G(\vs) \vu_s $
Core Idea
ATACOM - Acting on the TAgent Space of COnstraint Manifold

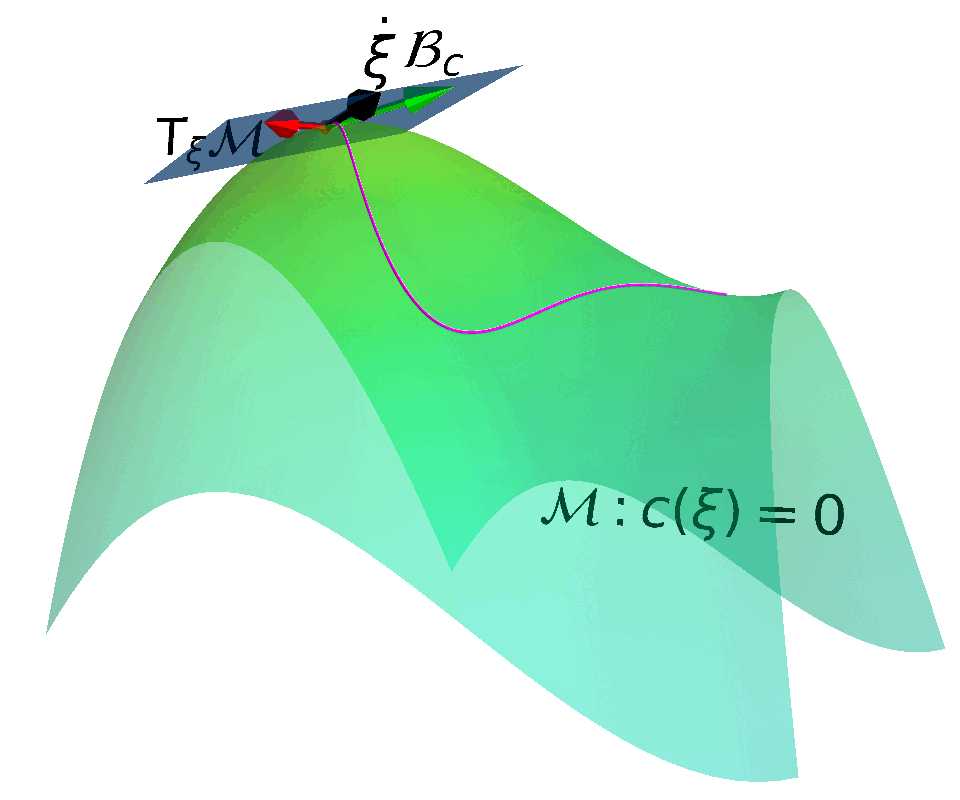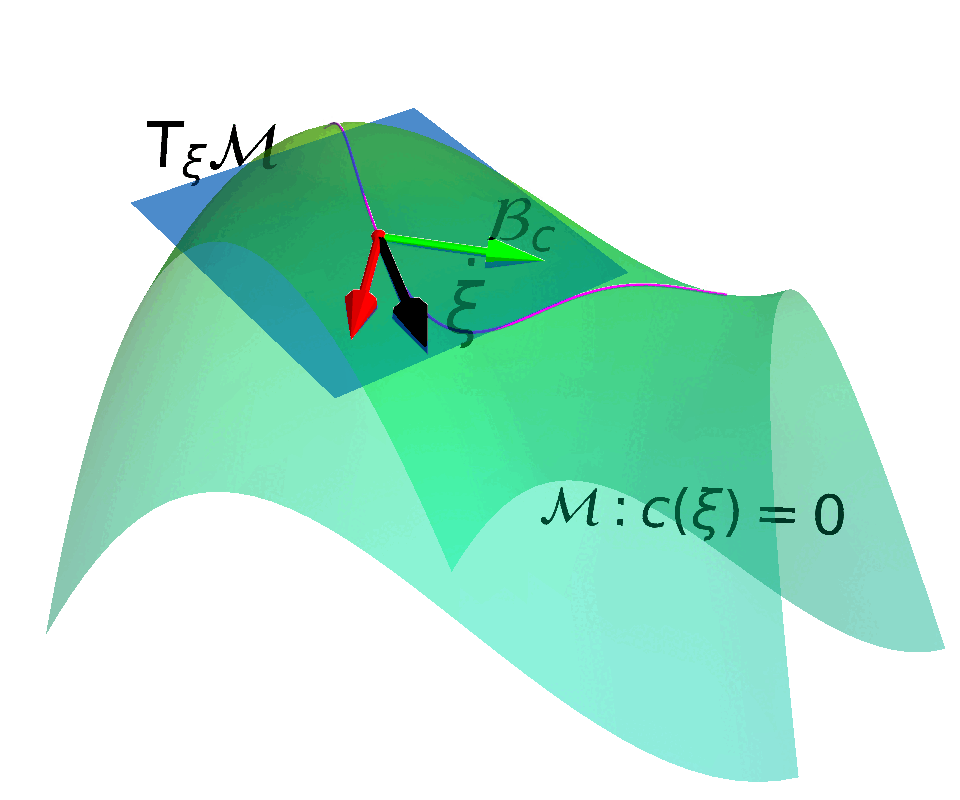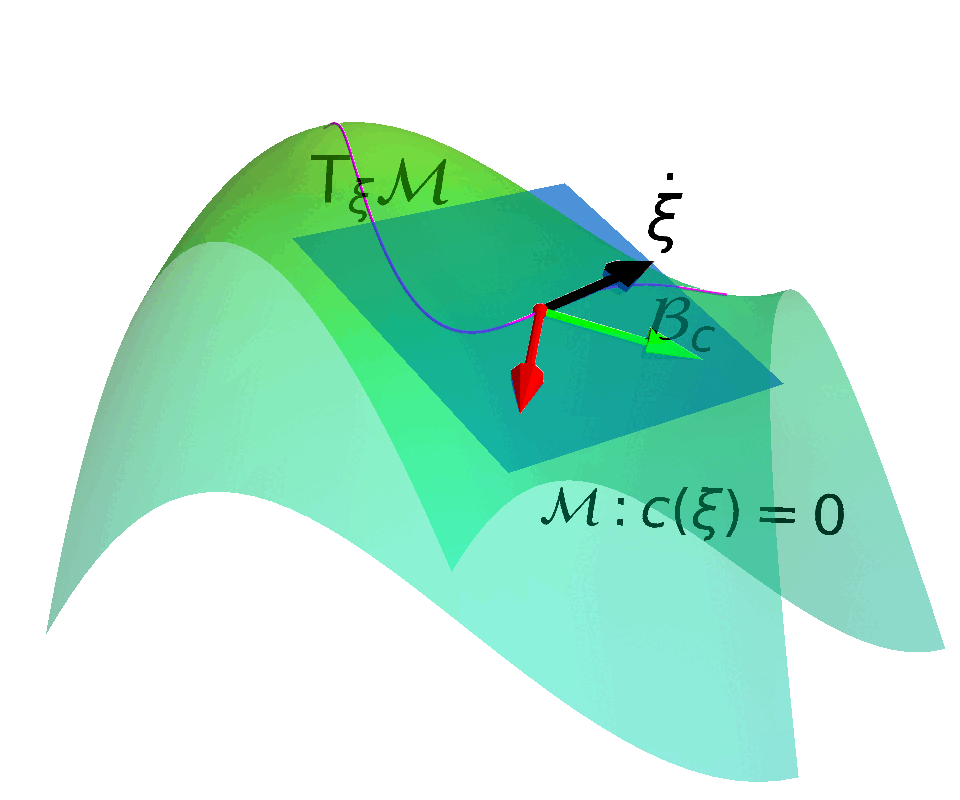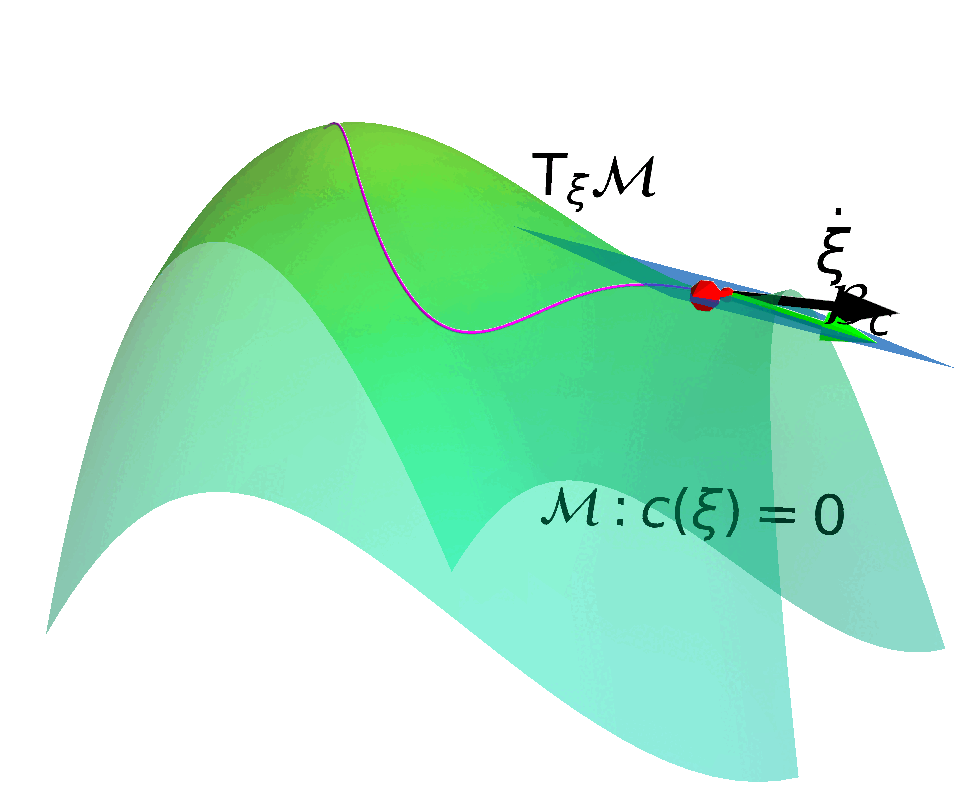
Constraint Manifold
Safe set $$\quad \mathcal{C} = \{\vs \in \mathcal{S} | k(\vs) < 0 \}$$
Constraint manifold in the augmented state space $$ \MM = \{(\vs, \vmu) \in \mathcal{S} \times \mathbb{R}^{+} | c(\vs, \vmu) \coloneqq k(\vs) + \vmu = 0\} $$
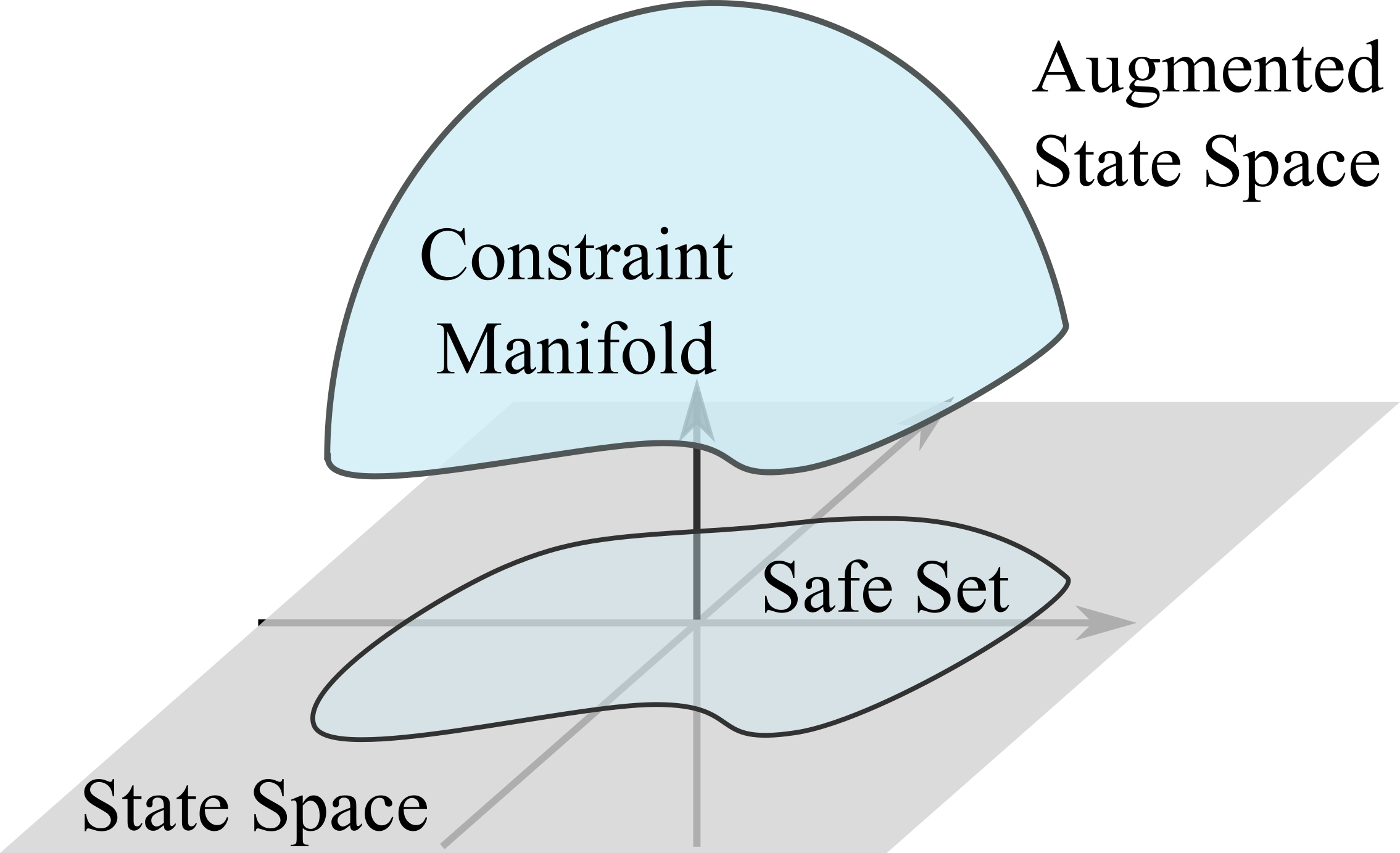
Safe set $$\quad \mathcal{C} = \{\vs \in \mathcal{S} | k(\vs) < 0 \}$$
Constraint manifold in the augmented state space $$ \MM = \{(\vs, \vmu) \in \mathcal{S} \times \mathbb{R}^{+} | c(\vs, \vmu) \coloneqq k(\vs) + \vmu = 0\} $$
Velocity tangent to the manifold $$\mathrm{T}_{(s, \mu)}\MM =\left\{ (\dot{\vs}, \dot{\vmu}) | \dot{c}(\vs, \vmu) = \begin{bmatrix} \mJ_k & \mathbb{I} \end{bmatrix} \begin{bmatrix} \dot{\vs} \\ \dot{\vmu} \end{bmatrix} = \vzero \right\}$$
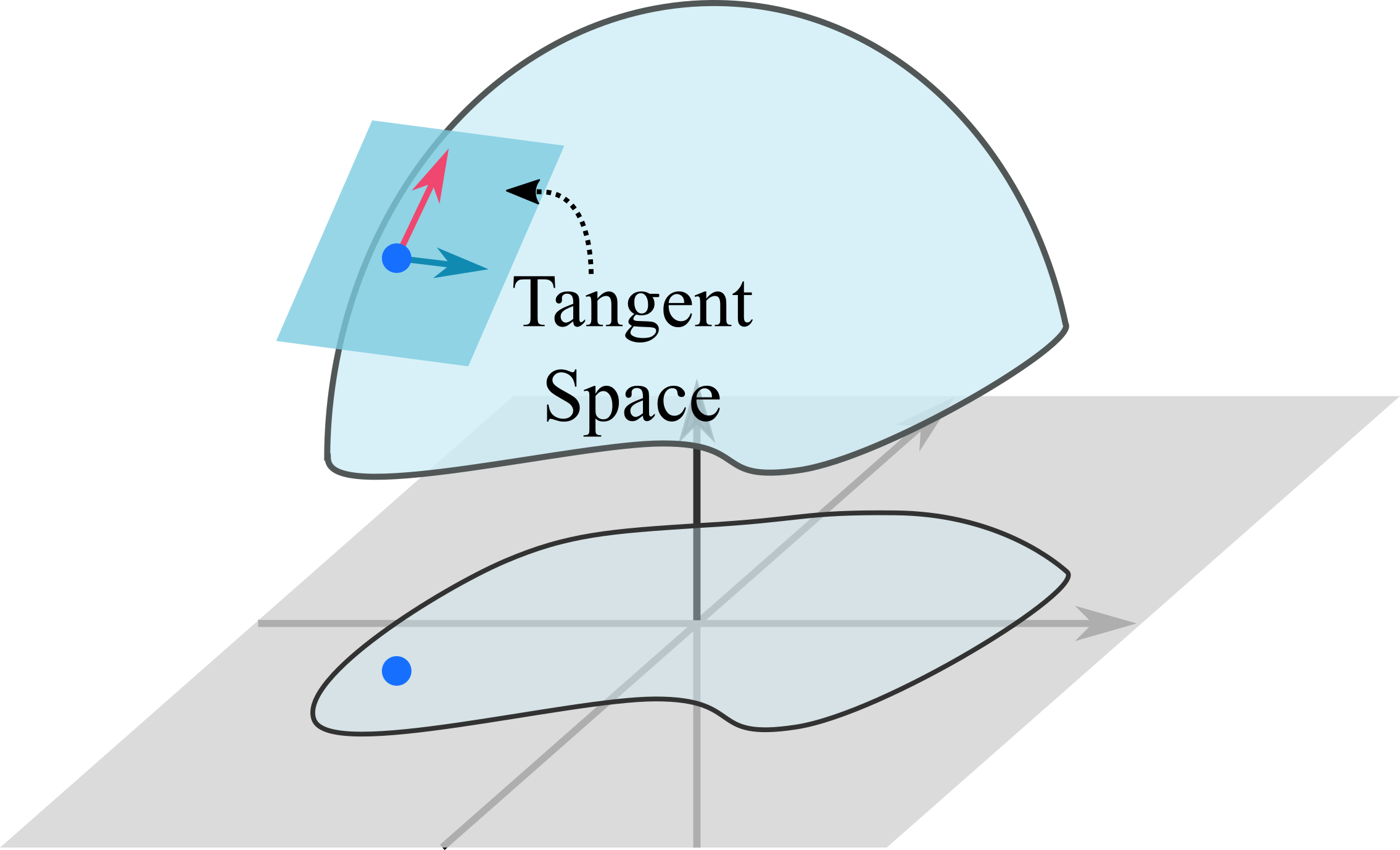
ATACOM
Acting on the TAngent space of the COnstraint Manifold (ATACOM)
$\begin{bmatrix} \vu_s \\ \vu_\mu \end{bmatrix} = \textcolor{b2e061}{\underbrace{-\mJ_u^{\dagger} \vpsi}_{\text{Drift Comp.}}}$ $\textcolor{#fd7f6f}{\underbrace{- \lambda \mJ_u^{\dagger} \vc}_{\text{ Contraction }}}$ $\textcolor{7eb0d5}{\underbrace{+ \mB_u \va }_{\text{ Tangential }}} $
- Nullspace matrix $\mB_u$ such that $\mJ_u \mB_u = \vzero$. $\mB_u$ determines the tangent space basis.
- Drift compensation term and contraction term are determined by $\vs$.
- ATACOM constructs a safe action space $\va \in \mathcal{A}$ and a mapping $W(\va): \mathcal{A} \rightarrow \mathcal{U}$.
- Can be used in various RL methods as all actions are sampled in the safe action space.
Robot Air Hockey Experiment
- Task: hit the randomly initialized puck to the goal
- Control: robot's joint velocity
- Observation: puck and robot's Joint position/velocity
- Constraint:
- Mallet stays on the table surface and within the boundary
- Robot do not collide with the table
- Joint position within the limits
- RL algorithm: ATACOM-SAC
- Fine-tuning with real world interactions
- Data collection: 100 episodes (~48min)
- Total training: 3000 episodes (~24h)
Training setup in the real world
Success rate
| Simulation | 86% |
| Zero-shot transfer | 12% |
| Fine tuning | 71% |
Hitting Velocity
| Simulation | 0.92m/s |
| Zero-shot transfer | 0.97m/s |
| Fine tuning | 0.97m/s |
More Applications
Mobile Robot with Differential Drive
15 Moving Obstacles
More Applications
Human Robot Interactions
Simulated Scenario
Wrap Up
ATACOM: Safe Exploration on the Tangent Space of the Constraimt Manifold

Safe Exploration in Dynamic Environment

Learning Safe Policy in the Human Robot Interaction Scenario
