Safe Reinforcement Learning of Dynamic High-Dimensional Robotic Tasks: Navigation, Manipulation, Interaction
Puze Liu, Kuo Zhang, Davide Tateo, Snehal Jauhri, Zhiyuan Hu, Jan Peters, and
Georgia Chalvatzaki
Techinal University Darmstadt
Manipulation: TableEnv, ShelfEnvSim


In the manipulation task, we pre-trained a ReDSDF model to construct the constraint function. The video on the right shows the point cloud at a distance of 0.03 cm.
Manipulation: TableEnv, ShelfEnv
After two million training steps, the final policy learned with ATACOM reaches the target smoothly and quickly. We validate our trained policy in a real shelf environment to reach two randomly placed targets.
Manipulation: TableEnv, ShelfEnv
TableEnv
ShelfEnvSim
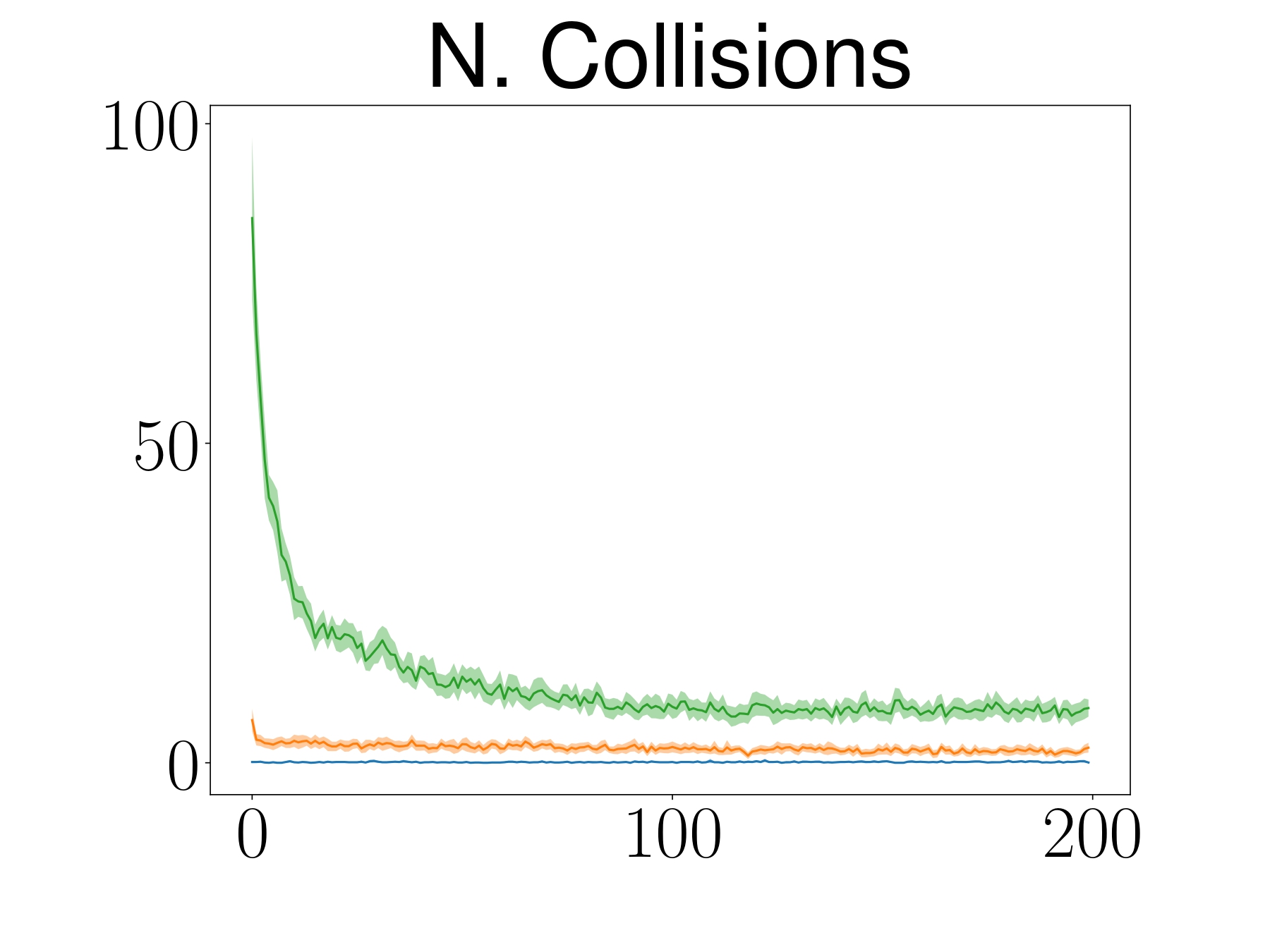
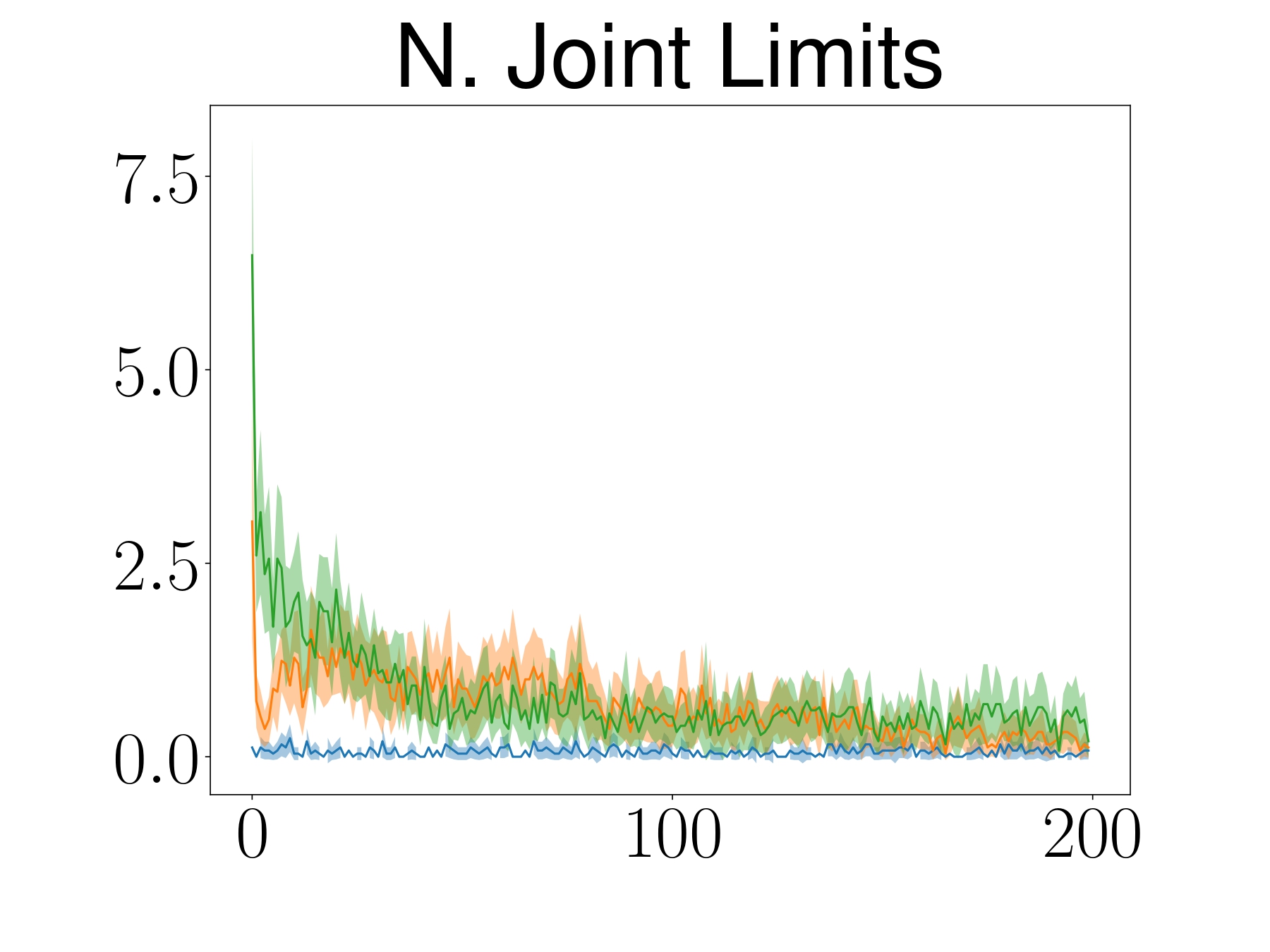

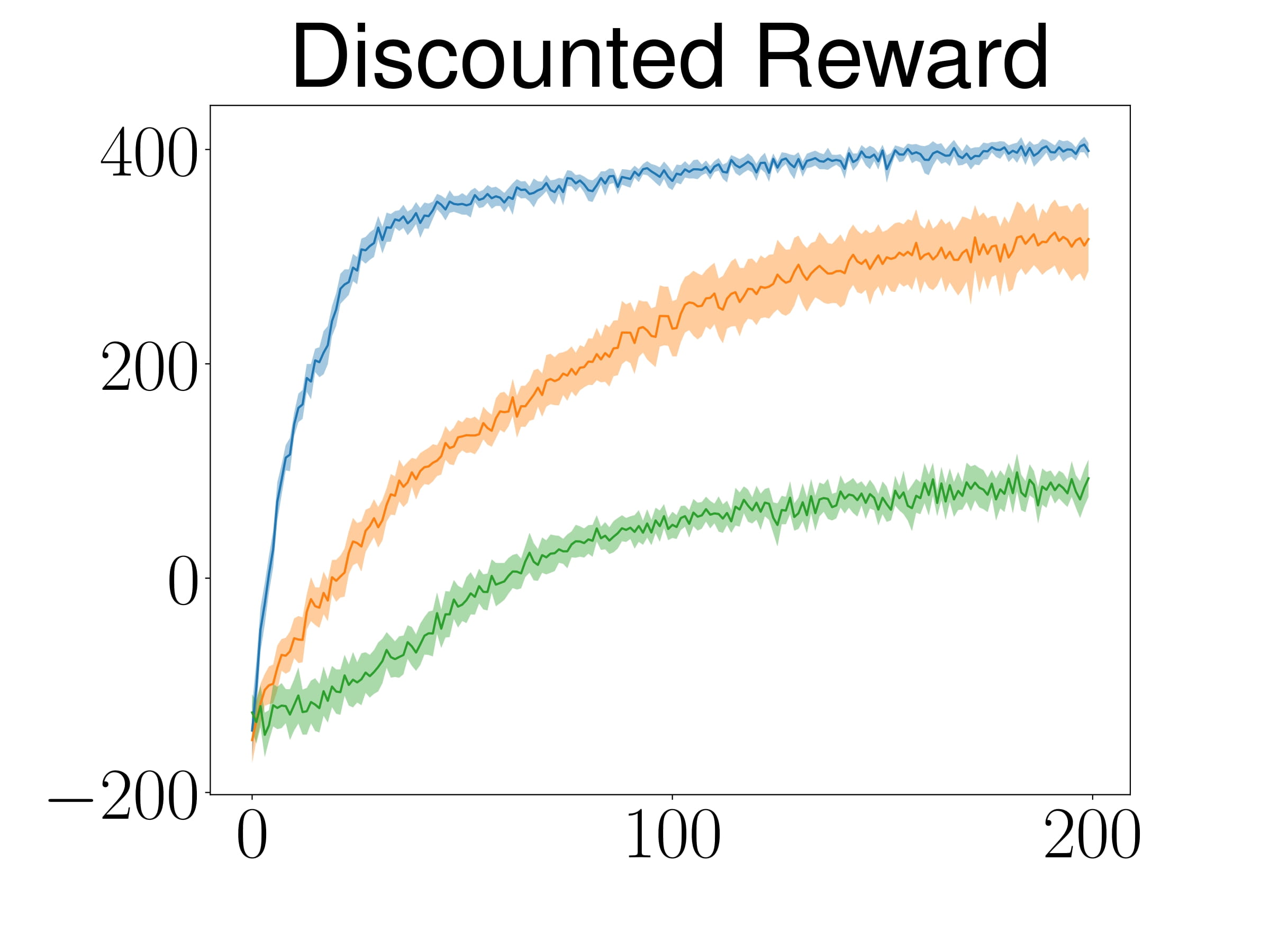
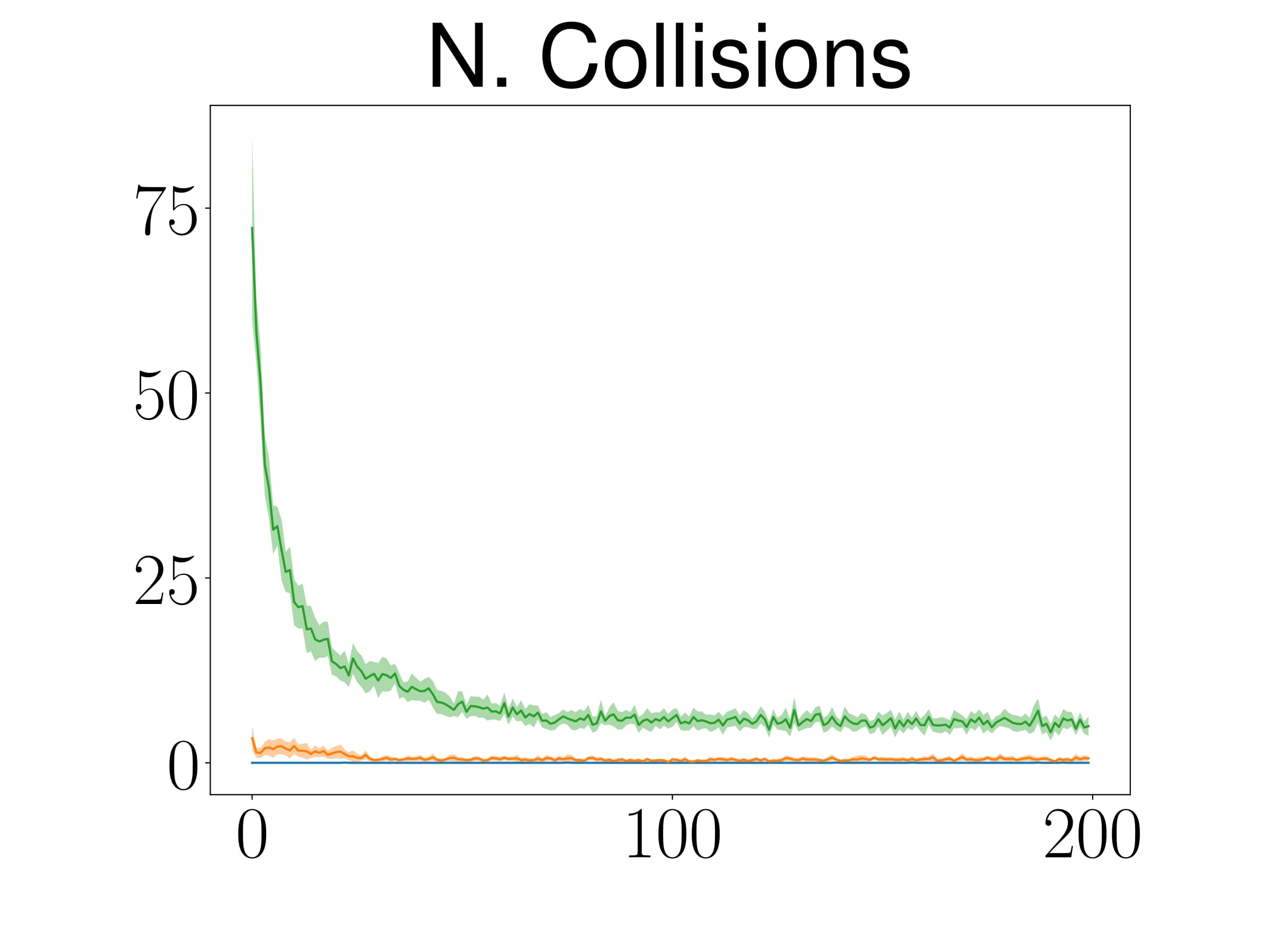
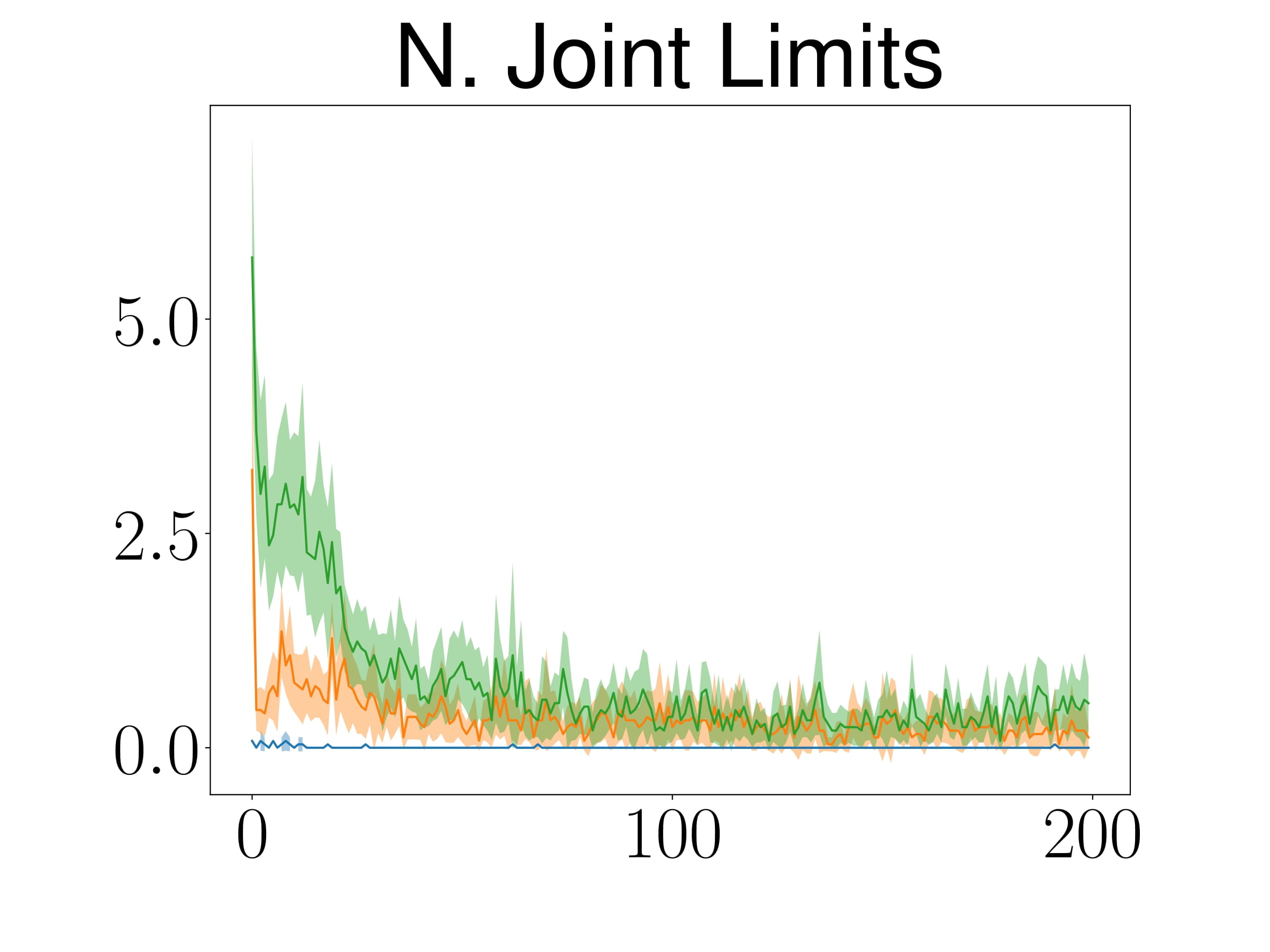
Comparing ATACOM with baselines, ATACOM learns faster and achieves better results for both tasks while having almost zero collisions and fewer joint limit violations.
Navigation
SAC
The vanilla SAC agent learns how to reach the target in the Navigation task.
However, the high penalty for collisions does not help to learn a safe behavior, as the collision terminates the episodes.
Navigation
SAC
SafeLayer
In some episodes, the SafeLayer method tries to avoid the collision, but it does not always succeed. This method only corrects the action once the constraints are violated which is too late to ensure safety.
Navigation
SAC
SafeLayer
ATACOM
Instead, ATACOM achieves a predictive manner thanks to the slack variables.
The agent will shrink its action space as the distance to the obstacle decreases.
Navigation
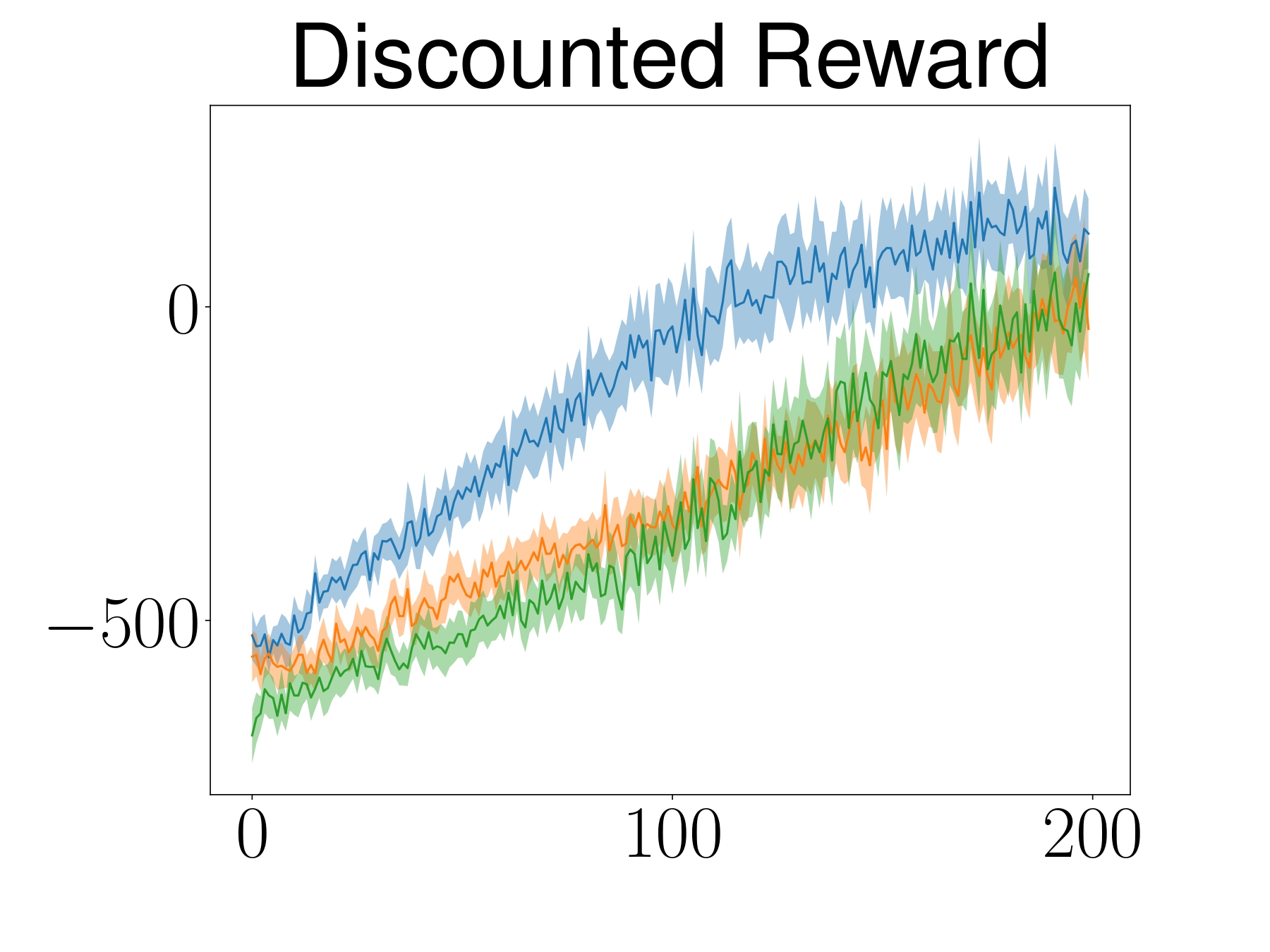
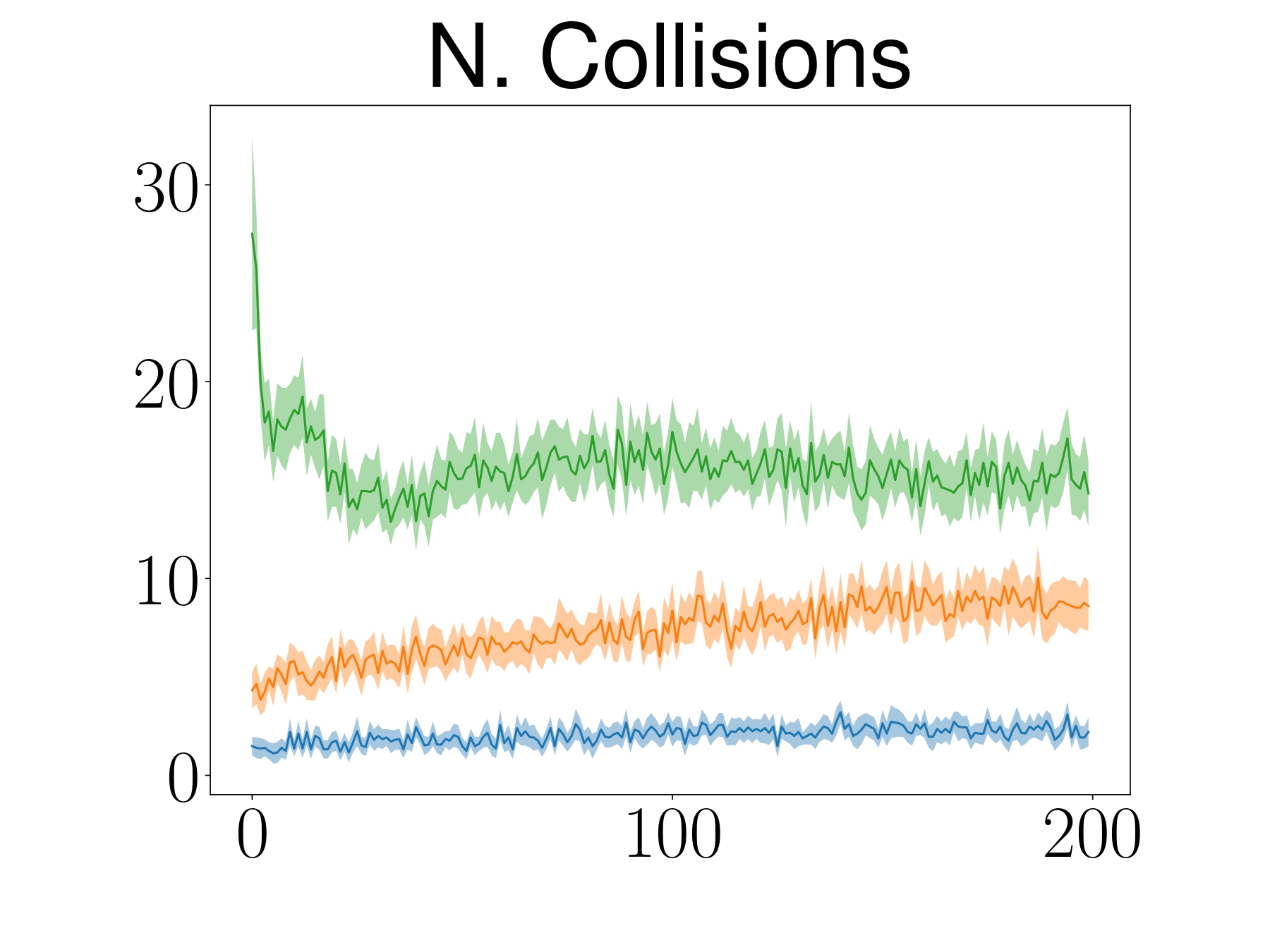
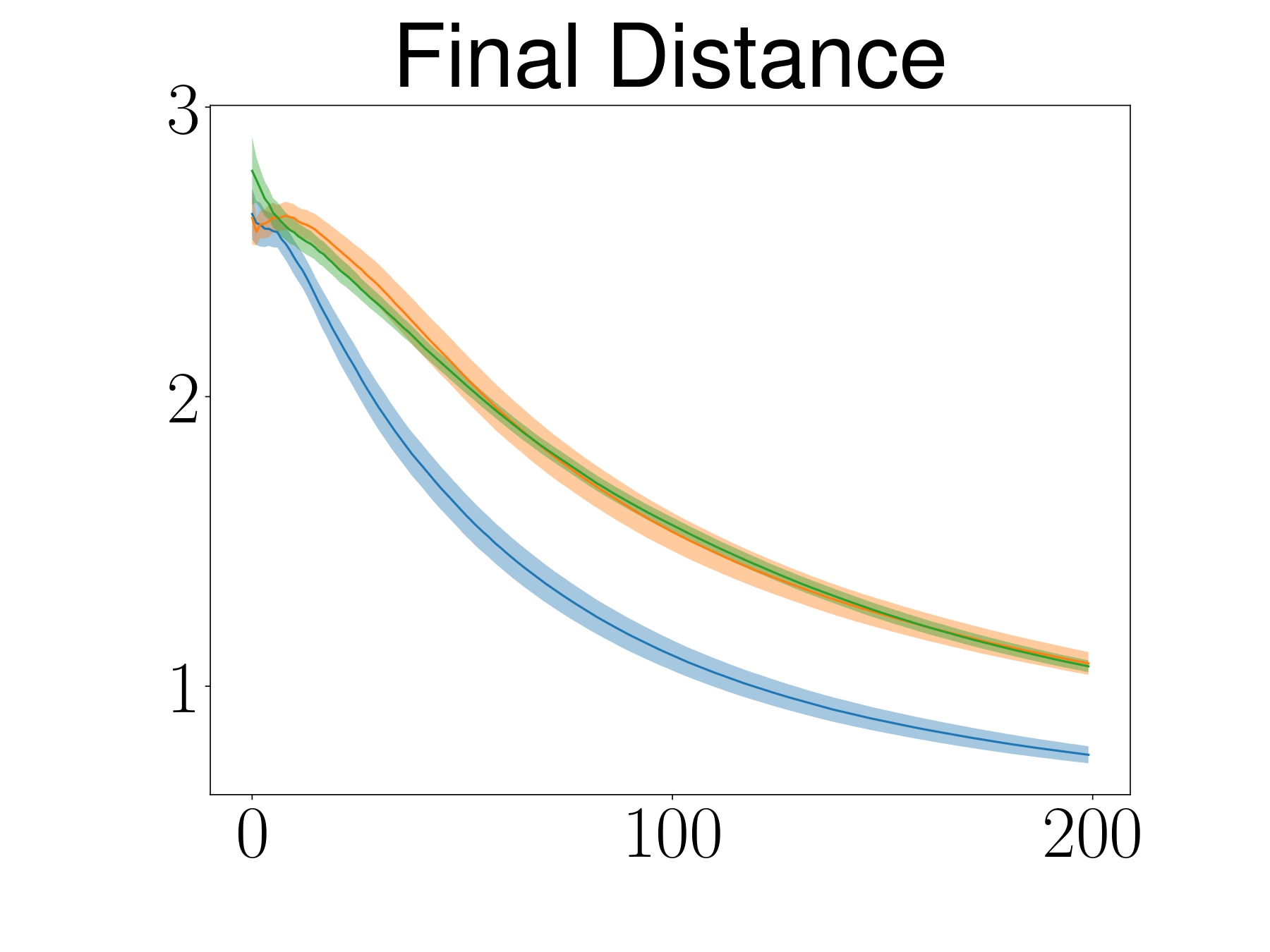
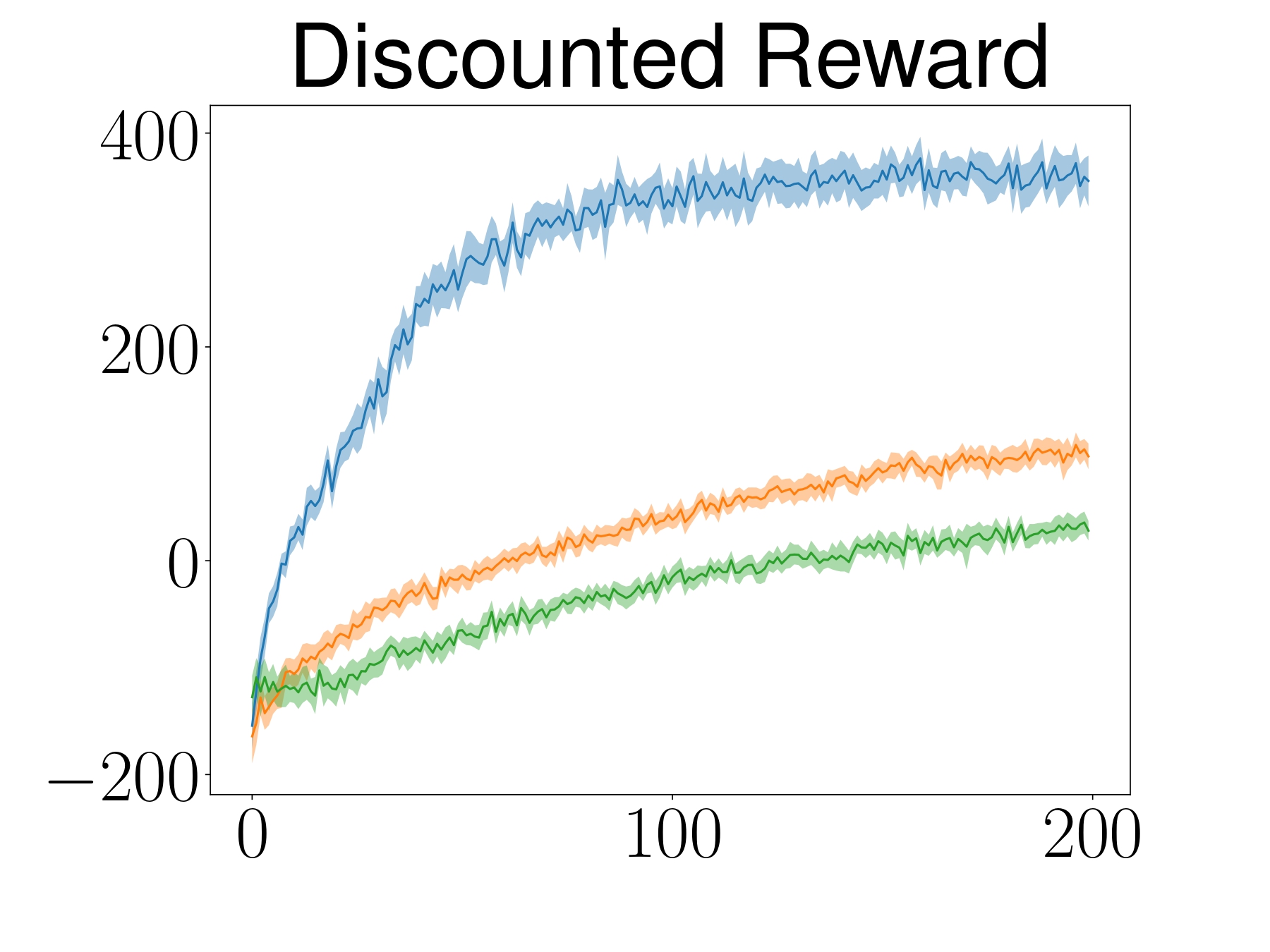
The learning curve depicts the mean and 95% confidence interval of 25 random seeds.
ATACOM outperforms baselines in terms of learning behavior and also safety.
Human Robot Interaction: Real-Sim
In the HRI experiment, we rely on a motion capture system to get an accurate human pose estimate for querying the human-ReDSDF. The human is instructed to ignore the robot by looking at the phone. The red point cloud shows the distance field of 0.05m for all obstacles, including human, table, and TIAGo robot body.
Human Robot Interaction
3x speed
We validate the ATACOM-learned policy in multiple trials with various human movements. The robot carries the cup properly while avoiding colliding with the human.
Human Robot Interaction
3x speed