Robot Air Hockey Challenge
2023
Organizers
Sponsor
Huawei
Motivation
- Impressive progress in the Machine Learning methods.
- Impressive progress in the Machine Learning methods.
- Fast development of robot hardware and novel robotic applications


- Impressive progress in the Machine Learning methods.
- Fast development of robot hardware and novel robotic applications
- Successful integration in Robot Learning
Diffusion Policy, Cheng Chi, et al.

Code as Policy, Jacky Liang, et al.
- Impressive progress in the Machine Learning methods.
- Fast development of robot hardware and novel robotic applications
- Successful integration in Robot Learning
- But many questions remain open ...
- Can ML improve robot performance in highly dynamic and reactive tasks?
- How to address safety issues when learning in complex robotic systems?
- Can black-box approaches compete with structured policies?
- Can we learn with a limited amount of data?
- Are current learning methods adequate for high-precision tasks?
Why Robot Air Hockey is Interesting?
- Highly dynamic task that requires robot to be reactive and agile.
- Limited working space resulting in strict safety requirements.
- Complex task incorporating low-level motor skills with high-level tactics.
- Robust solution that adapts to different opponents.
- Exploit the robot's capability to achieve high-speed motion.
Optimization-based Trajectory Generation
How to generate high-speed hitting trajectories on the table surface in real-time within robot's performance limits?
Sequential Trajectory Optimization
- Find optimal hitting configuration by maximizing the measure of manipulability.
- Find the maximum hitting speed at that configuration.
- Plan a Cartesian trajectory.
- Leverage the robot redundancy to find a feasible joint trajectories.




How to generate high-speed hitting trajectories on the table surface in real-time within robot's performance limits?
Sequential Trajectory Optimization
- Find optimal hitting configuration by maximizing the measure of manipulability.
- Find the maximum hitting speed at that configuration.
- Plan a Cartesian trajectory.
- Leverage the robot redundancy to find a feasible joint trajectories.
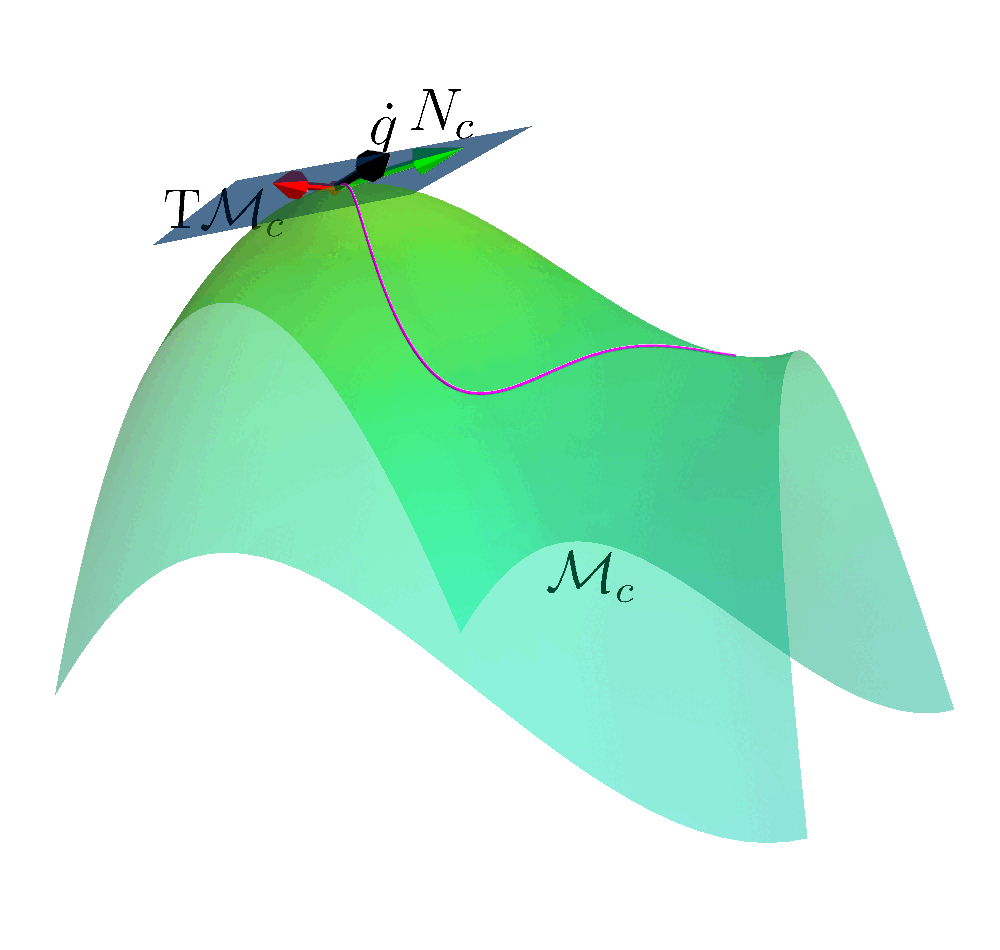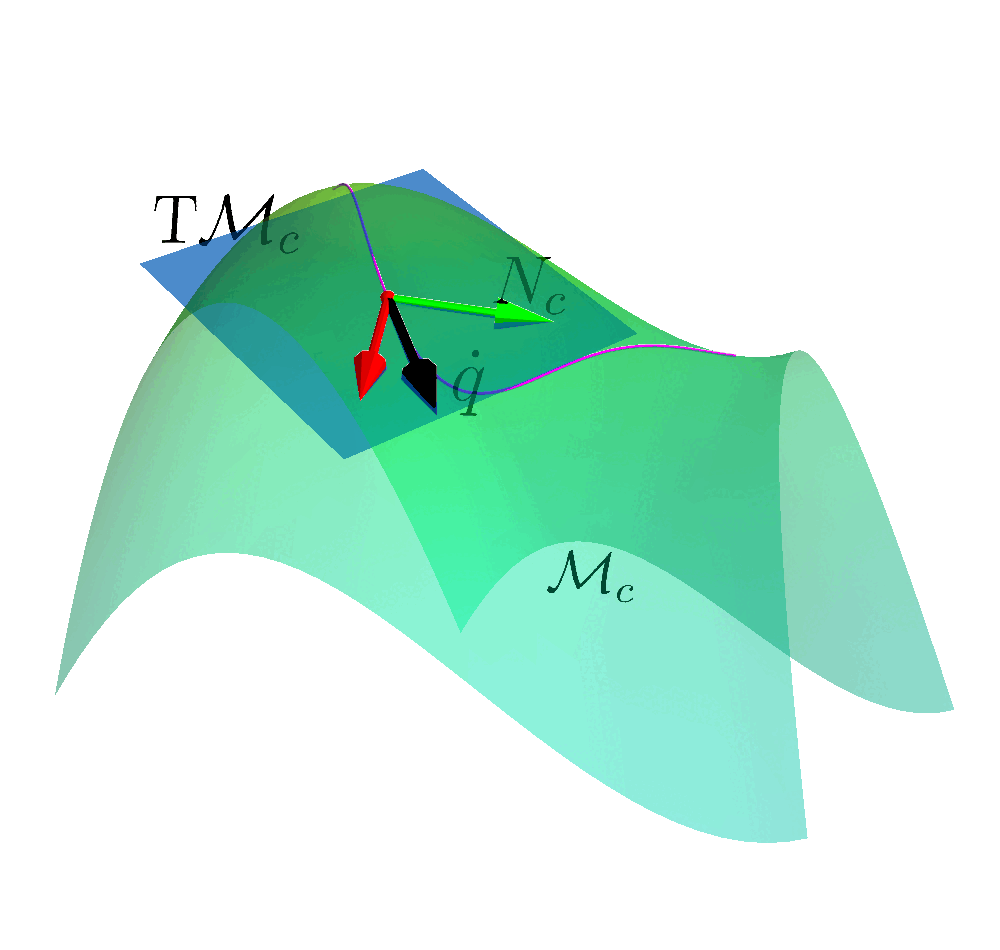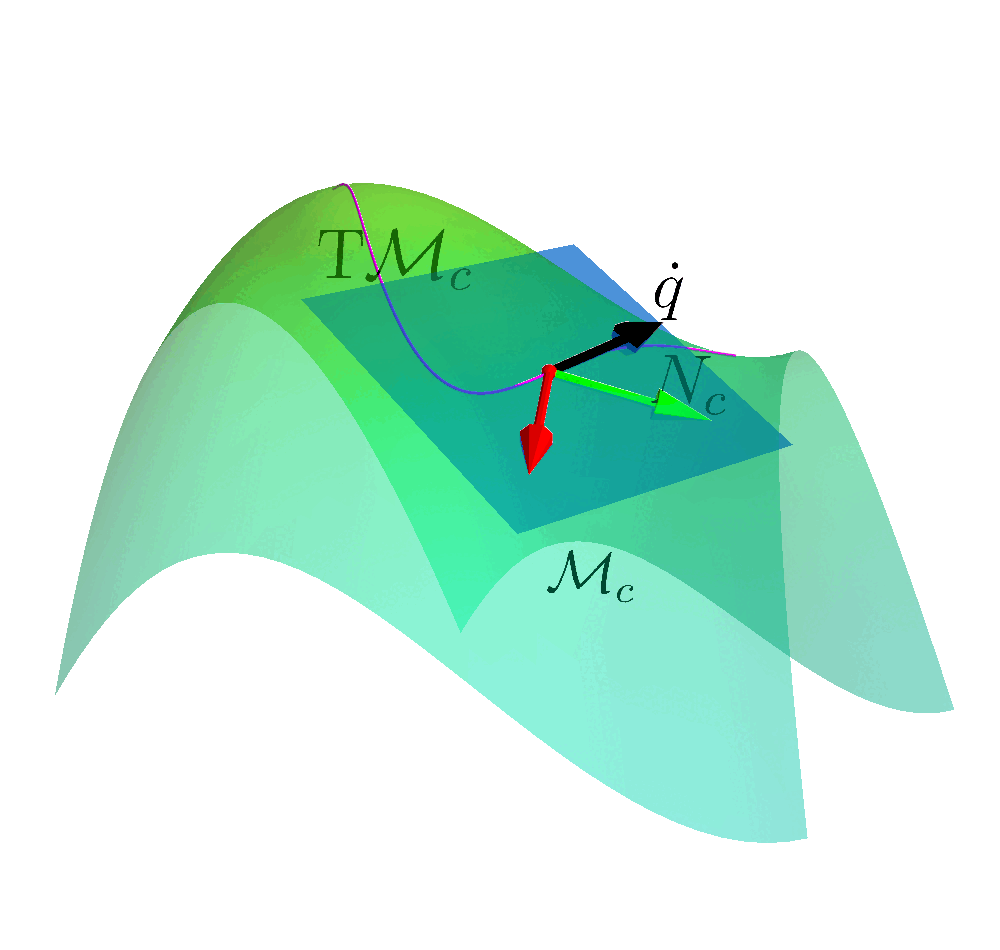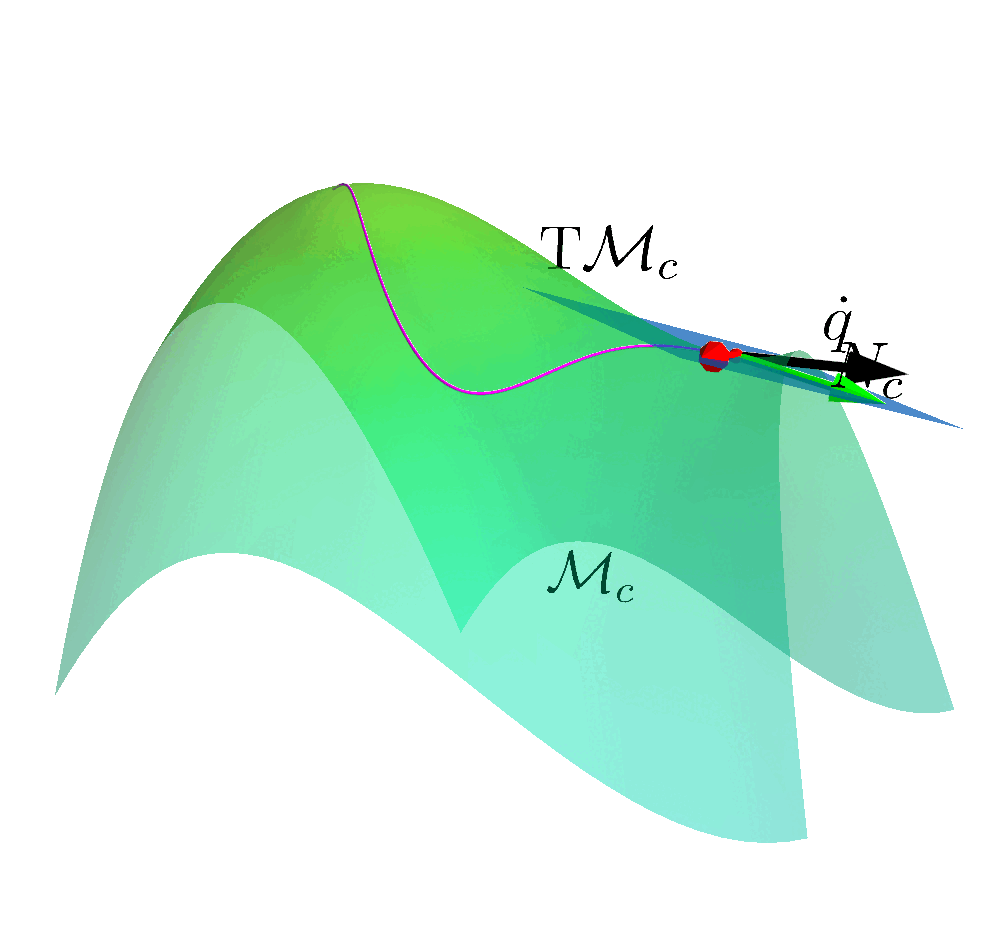
Safe Exploration on the Constraint Manifold
How to ensure safety at every step of the exploration process?
- Build any action space so that all actions within the space are safe.
-
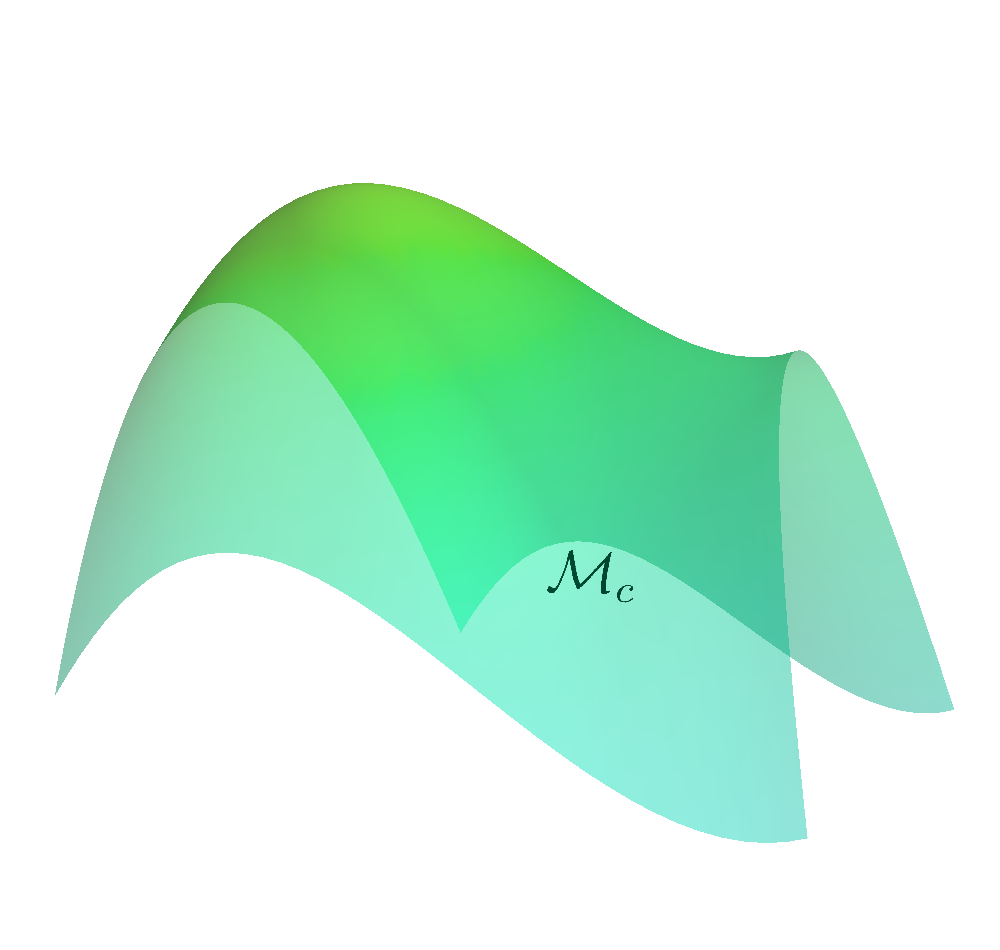
Create a safe set (Manifold) from the constraints.
$$\MM_c = \left\{ (\vq, \vmu) \left| c(\vq, \vmu) = \begin{bmatrix} \mathcal{E}(\vq) \\ \mathcal{I}(\vq) + h(\vmu) \end{bmatrix} \right. = \vzero \right\}$$
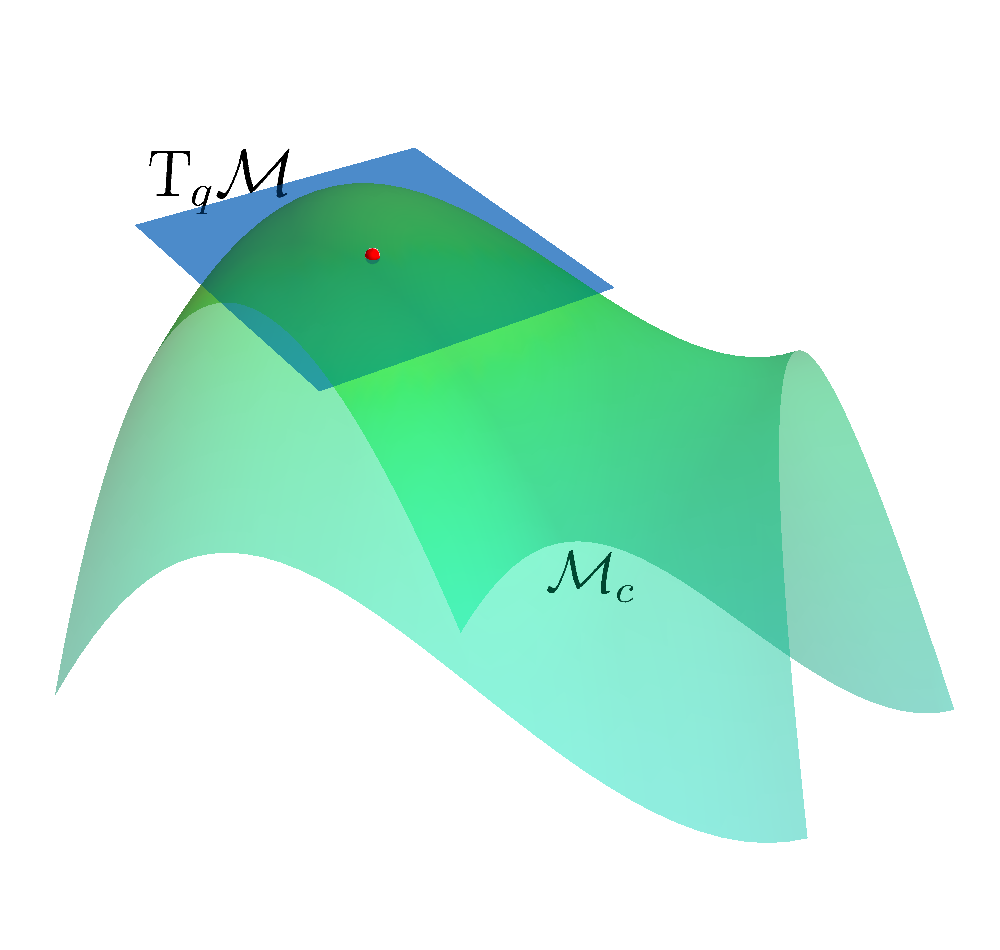
- Determine the Tangent Space $\mathrm{T}_q \MM$ of the Constraint Manifold at state.
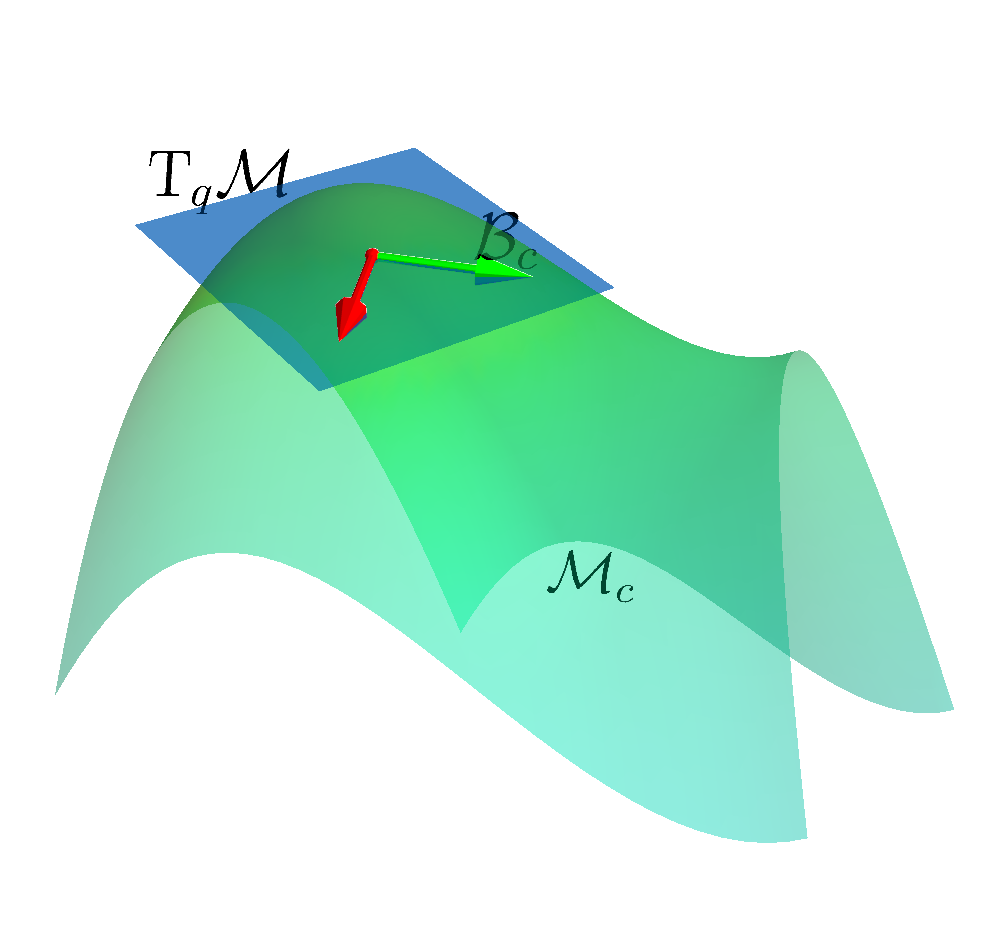
- Construct a linear basis in the tangent space $\mathcal{B}_c$.
- All actions sampled are safe.
How to ensure safety at every step of the exploration process?
- Build any action space so that all actions within the space are safe.
-
Create a safe set (Manifold) from the constraints.
$$\MM_c = \left\{ (\vq, \vmu) \left| c(\vq, \vmu) = \begin{bmatrix} \mathcal{E}(\vq) \\ \mathcal{I}(\vq) + h(\vmu) \end{bmatrix} \right. = \vzero \right\}$$
- Determine the Tangent Space $\mathrm{T}_q \MM$ of the Constraint Manifold at state.
- Construct a linear basis in the tangent space $\mathcal{B}_c$.
- All actions sampled are safe.
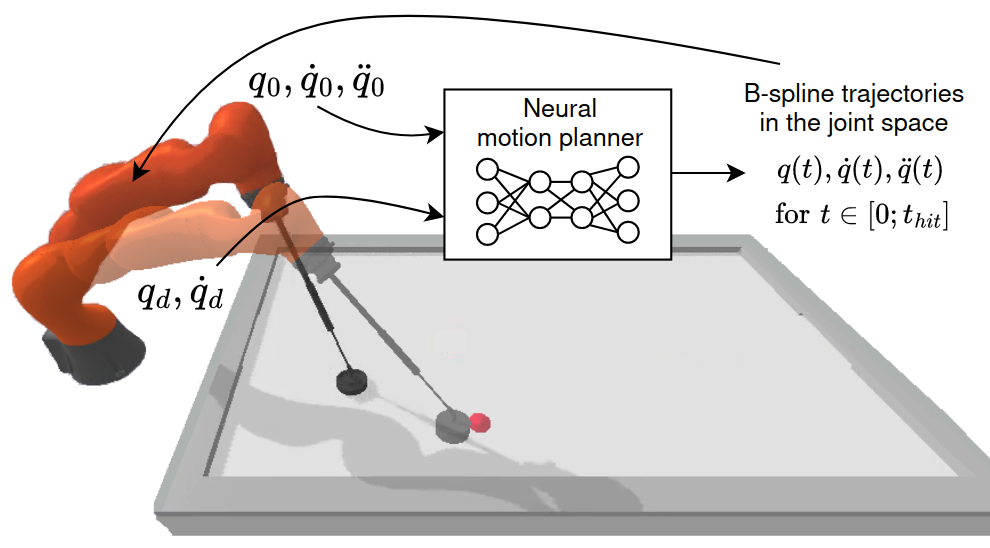
Kinodynamic Planning under Constraints
Can we pretrain a motion planner and utilize it in real-time motion generation?
- B-Splines parameterize both joint configuration and time evolutions.
- Neural Network predicts control points given the boundary constraints.
- Constraints are integrated into the loss with adaptive weights.
- Planning and replanning can be achieved in milliseconds.
Can we pretrain a motion planner and utilize it in real-time motion generation?
- B-Splines parameterize both joint configuration and time evolutions.
- Neural Network predicts control points given the boundary constraints.
- Constraints are integrated into the loss with adaptive weights.
- Planning and replanning can be achieved in milliseconds.
Can we pretrain a motion planner and utilize it in real-time motion generation?
- B-Splines parameterize both joint configuration and time evolutions.
- Neural Network predicts control points given the boundary constraints.
- Constraints are integrated into the loss with adaptive weights.
- Planning and replanning can be achieved in milliseconds.
Challenge Structure
Objective: Develope Safe, Reactive and Robust Learning Agent
Objective: Develope Safe, Reactive and Robust Learning Agent
Two Competition Stages: Qualifying / Tournament
Objective: Develope Safe, Reactive and Robust Learning Agent
Two Competition Stages: Qualifying / Tournament
Development: Ideal Simulation
Objective: Develope Safe, Reactive and Robust Learning Agent
Two Competition Stages: Qualifying / Tournament
Development: Ideal Simulation
Evaluation: Modified Evaluator
including disturbances, observation noise, lost of tracking, non-ideal tracking controller
Objective: Develope Safe, Reactive and Robust Learning Agent
Two Competition Stages: Qualifying / Tournament
Development: Ideal Simulation
Evaluation: Modified Evaluator
including disturbances, observation noise, lost of tracking, non-ideal tracking controller
Safety Requirements:
EE stay on table surface and within table's boundary / Joint position/velocity limits
Objective: Develope Safe, Reactive and Robust Learning Agent
Two Competition Stages: Qualifying / Tournament
Development: Ideal Simulation
Evaluation: Modified Evaluator
including disturbances, observation noise, lost of tracking, non-ideal tracking controller
Safety Requirements:
EE stay on table surface and within table's boundary / Joint position/velocity limits
Evaluation Metric:
success rate, computation time, constraint violations
Qualifying Stage
Hit
Score a goal while the oppoenent moves in a fixed pattern
Defend
Intercept the puck to prevent it from scoring or bouncing to the opponent's side
Prepare
Control the puck to move it from the edge area to the center of the table.
Tournament Stage
Competition
Two teams play against each other in a 15-minute game
Double round-robin schedule
The team with the highest cumulative score wins
Participants
Registered Teams
47
Qualified Teams
11
Tournament Teams
7
Registered Teams
47
Qualified Teams
11
Tournament Teams
7
Africa
1
Asia
8
Europe
19
North America
8
Unknown
11
Evaluation of Modification Factors: Hit

Normalized Success Rate
| Min | Max | Mdn | Avg. | |
|---|---|---|---|---|
| Ideal | 1.0 | 1.0 | 1.0 | 1.0 |
| Model Mis. | 0.903 | 1.268 | 1.000 | 0.996 |
| Obs. Noise | 0.700 | 1.154 | 1.049 | 0.970 |
| Disturbance | 0.719 | 1.731 | 0.964 | 0.918 |
| Track. Lost | 0.600 | 1.439 | 0.940 | 0.914 |
| All Factors | 0.535 | 1.461 | 0.800 | 0.752 |
*Red entry correspond to the factors that has the biggest impact
*Performance are of each team is normalized based on the success rate in ideal env
Evaluation of Modification Factors: Defend

Normalized Success Rate
| Min | Max | Mdn | Avg. | |
|---|---|---|---|---|
| Ideal | 1.0 | 1.0 | 1.0 | 1.0 |
| Model Mis. | 0.918 | 1.084 | 1.000 | 0.993 |
| Obs. Noise | 0.846 | 1.012 | 0.989 | 0.970 |
| Disturbance | 0.605 | 1.028 | 0.913 | 0.878 |
| Track. Lost | 0.615 | 0.984 | 0.763 | 0.818 |
| All Factors | 0.404 | 0.930 | 0.589 | 0.705 |
*Red entry correspond to the factors that has the biggest impact
*Performance are of each team is normalized based on the success rate in ideal env
Evaluation of Modification Factors: Prepare

Normalized Success Rate
| Min | Max | Mdn | Avg. | |
|---|---|---|---|---|
| Ideal | 1.0 | 1.0 | 1.0 | 1.0 |
| Model Mis. | 0.890 | 1.152 | 0.985 | 0.969 |
| Obs. Noise | 0.674 | 1.122 | 0.975 | 0.954 |
| Disturbance | 0.739 | 1.099 | 0.948 | 0.922 |
| Track. Lost | 0.760 | 1.086 | 0.916 | 0.920 |
| All Factors | 0.526 | 0.904 | 0.782 | 0.790 |
*Red entry correspond to the factors that has the biggest impact
*Performance are of each team is normalized based on the success rate in ideal env
Schedule
| 09:15 - 09:45 | Robot Air Hockey and Other Physical Challenges: An Historical Perspective | Christopher G. Atkeson |
| 09:45 - 10:00 | Presentation from Challenge Finalists: Air-HocKIT | Gerhard Neumann |
| 10:00 - 10:15 | Presentation from Challenge Finalists: SpaceR | Andrej Orsula |
| 10:15 - 10:30 | Highlights from the Robot Air Hockey Challenge | |
| 10:30 - 10:45 | Presentation from the Challenge Finalists: AiRLIHockey | Ante Marić |
| 10:45 - 11:25 | Making Real-World Reinforcement Learning Practical | Sergey Levine |
| 11:25 - 11:55 | Panel Discussion | |
| 11:55 - 12:00 | Sponsor Talk & Award Ceremony |